
Unsupervised Machine Learning: Key Algorithms
- Oct 24, 2024
- 2 min read
In terms of dealing with unlabeled data, Unsupervised Machine Learning are applied. It enables the models to work with unlabeled data, allowing them to identify hidden patterns, relationships, and structures without predefined categories. The main objective of unsupervised learning is exploration and pattern recognition, making it valuable in areas like customer segmentation, anomaly detection, and recommendation systems.
Unlike supervised learning, where models learn from labeled examples, unsupervised learning finds intrinsic structures within data. Among the numerous techniques available, we discuss 3 essential types which are K-Means Clustering, Hierarchical Clustering, and Principal Component Analysis (PCA).
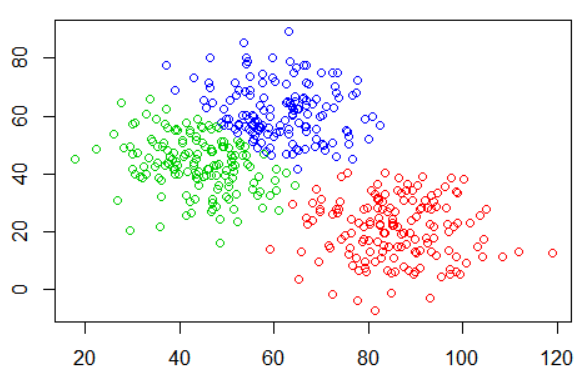
K-Means Clustering
One of the most widely used clustering algorithms, K-Means Clustering groups data points into K distinct clusters based on their similarities.
Algorithm
Randomly selecting K centroids.
Assigning each data point to the nearest centroid.
Recalculating the centroid based on the mean of all assigned points.
Repeating the process until centroids stabilize.

Strengths
Efficient for large datasets.
Works well with clearly separated clusters.
Challenges
Requires predefining K, which may not always be known.
Sensitive to outliers.
Hierarchical Clustering
Hierarchical clustering is a method that builds a tree-like structure of nested clusters, grouping data points based on their similarities. It uses either agglomerative (bottom-up) or divisive (top-down) clustering approaches.
Algorithm
Agglomerative clustering starts with individual points and merges them into larger clusters.
Divisive clustering starts with a large cluster and splits it into smaller sub-clusters.
The resulting hierarchy can be visualized using a dendrogram, which helps determine the optimal number of clusters.

Strengths
No need to predefine the number of clusters.
Useful for hierarchical or taxonomic data structures.
Provides interpretable visualizations of nested clusters.
Challenges
Computationally expensive for large datasets.
Once merged or split, clusters cannot be reassigned.
Choosing the right level of hierarchy can be subjective.
Principal Component Analysis (PCA)
PCA is a dimensionality reduction technique rather than a clustering algorithm. It simplifies large datasets by transforming them into fewer components while retaining most of the variance.
Algorithm
Identifies the principal components that explain the most variance.
Projects data onto a new space with fewer dimensions.
Helps visualize high-dimensional data more effectively.

Strengths
Useful for data compression and reducing computational cost.
Helps remove noise and redundant features.
Challenges
Can be hard to interpret since transformed features may not be easily explainable.
Assumes linear relationships in the data.



Comments